
In case you didn’t read my tutorial on predicting jazz genres extreme gradient boosting, check it out now! In short, I used Wikipedia articles on jazz albums to predict the genre of the albums. The method was over 80% accurate on the test set. So it gave a very reliable way of extrapolating genre data to albums whose specific subset of jazz was not specified on Wikipedia. I wondered if the same setup would be useful in deducing poets by their poetry.
I came across this dataset when looking for fun datasets to play with. It’s a collection of poems published on The Poetry Foundation. There are almost 14,000 poems in the dataset, and here are the top poets by number of poems:
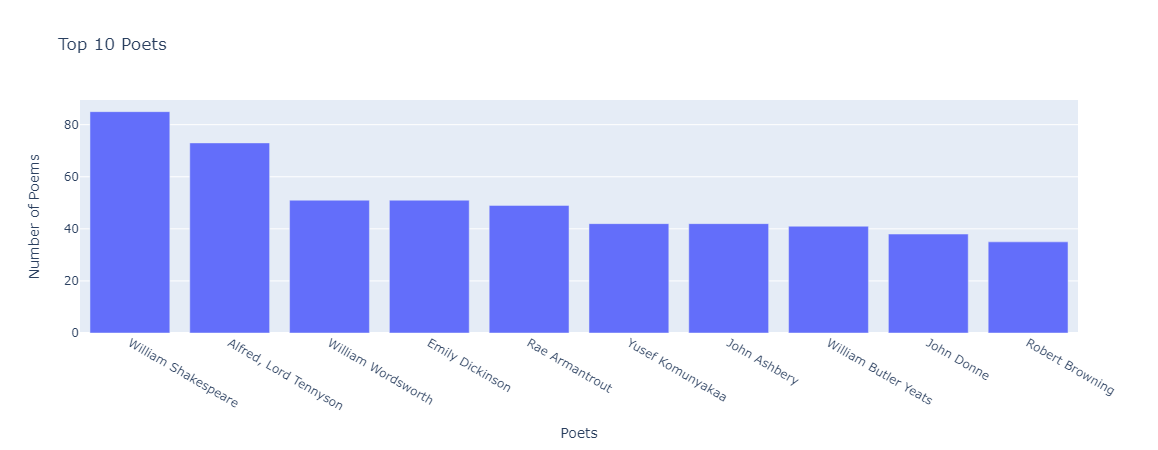
The training algorithm would essentially work the same way as with jazz genres. I use XGBoost to learn these ten poets as a function of their poems. Only, when I tried the method with this dataset, I only got 14% accuracy deducing poet by their poetry. What went wrong?
First, let’s put 14% accuracy in context. There are 10 possible poets here. Almost all of them have about 50 poems in the dataset. That means if I randomly guess which poet wrote a poem, I’d be right about 10% of the time. Our algorithm isn’t doing much better than a random guess.
Knowing your dataset
This is where knowing your dataset becomes essential in data science. Tennyson, Wordsworth, Dickinson, Yeats, and Browning were all writing in a similar time. Donne and Shakespeare were also close, temporally. It means they probably used English in similar ways. They used similar words, and more importantly, similar distributions of words. If that’s the case, then TF-IDF vectorization would have no strong statistical way of telling them apart. Because it completely depends on the distribution of keywords.
To test if that was the case, instead of using the top 10 poets in the dataset for my experiment, I took 10 of the top 100 poets at random and played the same game. Could my algorithm figure out which of the 10 wrote a given poem? I ran the randomized experiment 100 times, and the accuracy ranged from 16% to 62%, with an average of 33%. Now, that’s over 3x better than random guessing.
Between just 2 poets instead of 10, the average accuracy of this method is 70%. Better than the expected 50% from random guessing. Taking just Ashbery and Shakespeare from the top 10, XGBoost was able to tell them apart 88% of the time. Considering they have comparable numbers of poems in the dataset, that’s good evidence that our algorithm has learned something but struggles separating out poets from the same period, since it could tell these two apart.
TANSTAAFL (There ain’t no such thing as a free lunch)
There’s more that can be done here. No matter what I tried, TF-IDF and XGBoost alone couldn’t get the accuracy above 34% on average. This means the next step would be feature engineering. Essentially, creating new variables to train our algorithms on. This means putting in work to make your dataset more digestible to these algorithms.
One way to do this would be by finding extra data, such as articles on each of these poets. Since these sources would likely address the poet’s main themes, trying to group poems by theme might structure the data better for this analysis. Another possibility would be to extract themes and summaries from LLMs. By having an LLM characterize the sentiment, style, theme, or subject of a poem into one-or-few-word characterizations, we would have new ways to tell apart poets. A poem from Edgar Allen Poe might be summarized as “depressing” and “death” while Whitman might get “self-celebrating” and “open-hearted.” Our algorithm could use these new inputs as extra information to tell poets from the same period apart.